.png)
诚信、高效、团结、创新
诚信、高效、团结、创新
恭喜实验室硕士研究生张鳐以第一作者分别在国际多媒体领域顶级会议ACM International Conference on Multimedia (ACM MM)和信号处理高水平期刊IEEE Transactions on Vehicular Technology上发表学术论文成果。其中,ACM MM是中国计算机学会A类会议,在多媒体处理、计算机视觉与人工智能交叉领域享有较高学术声誉。
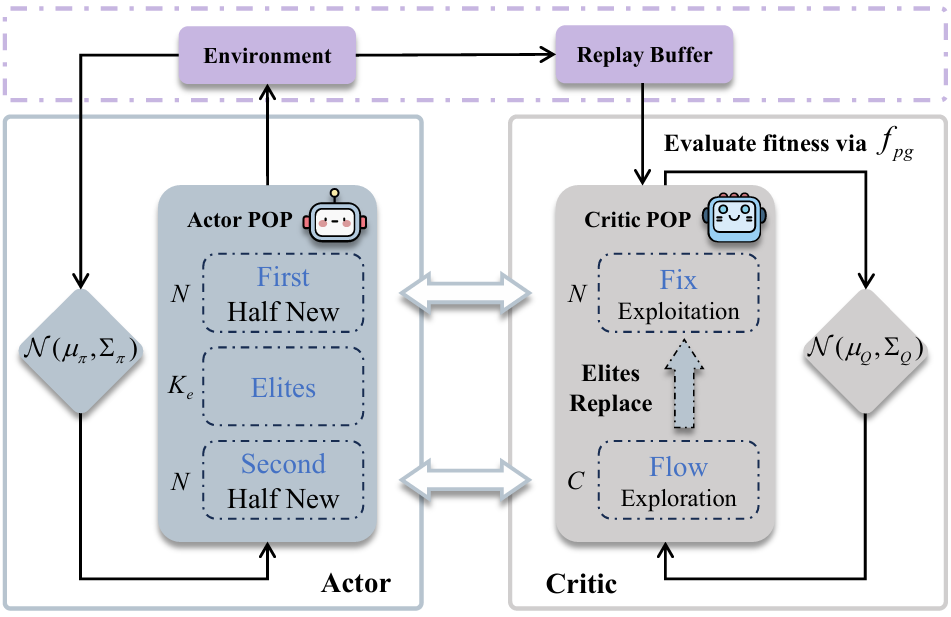
在ACM MM上发表的论文《Multimodal Dual Population Evolutionary Reinforcement Learning》创新性地提出了多模态双种群进化强化学习(M-DPERL),解决当前Actor-Population Critic框架中策略质量与多样性难以平衡的问题。在包含Ant、HalfCheetah、Humanoid等13个经典连续控制任务的系统性实验中,该方法在样本效率上超越基线方法19.2%,最终性能提升达17.1%。M-DPERL显著提升了智能体对复杂环境的结构化理解与决策多样性。该方法可广泛应用于机器人控制、游戏智能、自动驾驶等需在探索与利用间取得平衡的序列决策场景,为进化强化学习的实际落地提供了新的算法框架和理论支撑。
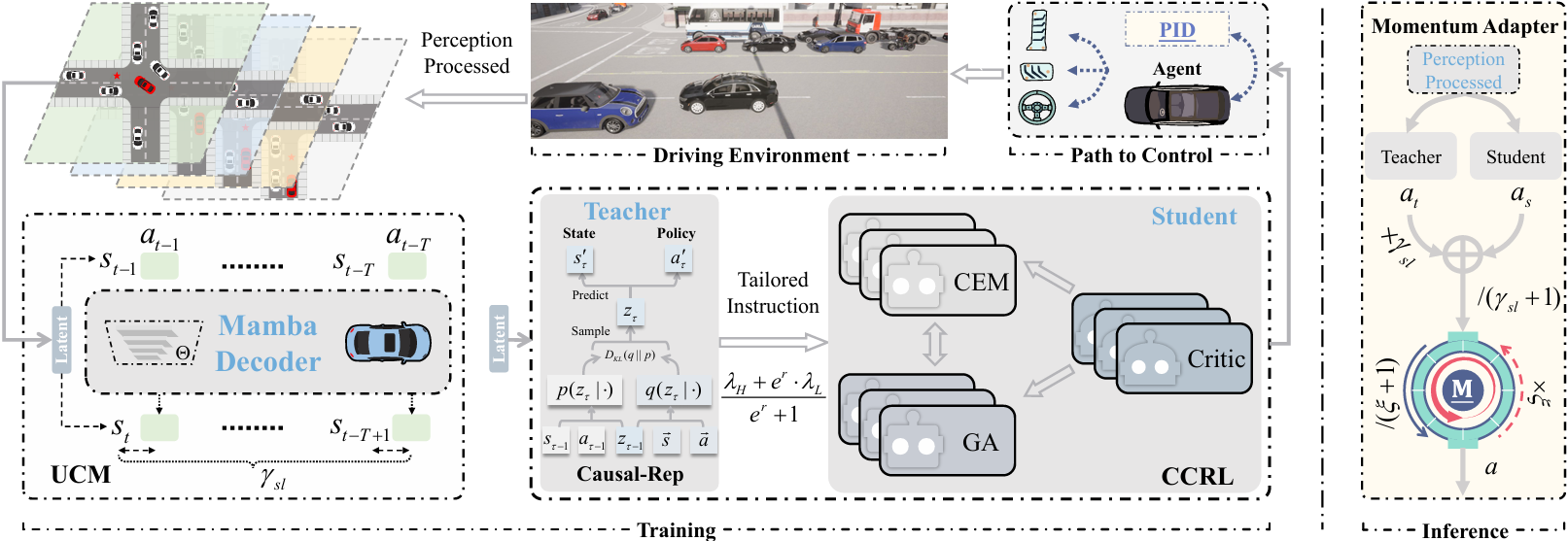
在 TVT 上发表的论文《Causal Representation-Augmented Joint Decision-Making for Autonomous Driving》提出了一种名为 CRAJ 的因果表示增强联合决策框架。该框架通过引入因果表示学习增强教师模型的推理与泛化能力,使其不仅能在训练阶段为学生模型提供自适应指导,还能在实际驾驶的推理阶段与学生协同完成实时决策。
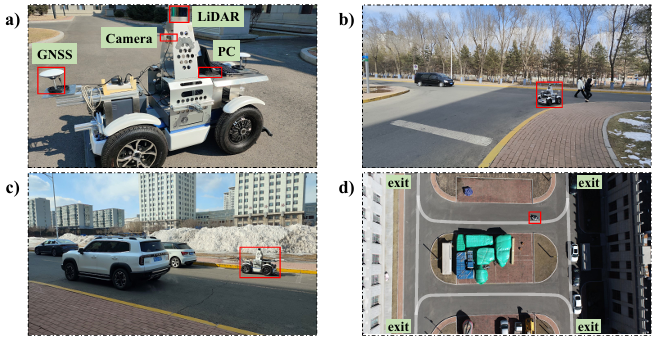
实验结果表明,该方法在 CARLA 仿真平台上的驾驶评分较现有方法提升超过19.5%,在现实场景测试中任务成功率提升16.4%。系统在雨天、夜间、无信号灯路口、环岛等多种复杂场景中均表现出优异的稳定性和适应性,实现了在保障安全的前提下提升决策智能性的目标。团队将继续致力于强化学习、因果表示与决策优化等方向的交叉研究,推动自动驾驶技术向更安全、更高效、更可信的方向发展。
编 辑 | 于 欣 欣